Keeping it boring (and relevant) with BM25F
Every field in computer science has its 'workhorse' techniques, those eminently reliable algorithms and data structures at the heart of many real-world applications. The databases field has B-trees and write-ahead logging, machine learning has gradient descent and logistic regression. For search, one of those key techniques is the BM25 ranking algorithm.
First introduced in 1994, BM25 eventually made its way into popular search engines like Apache Lucene and has been powering search bars across the internet for decades. Because it works well with keyword search engines, BM25 is efficient to compute over massive datasets. It also performs well in diverse settings, providing good out-of-the-box ranking in a variety of domains like site search, legal search, and more.
Sourcegraph supports keyword search like the other browser-based search bars you’re used to. When searching code, sometimes you know the exact name of a symbol, or are looking for an exact syntactic structure. But other times you just vaguely remember there was a method to determine an element’s priority in the queue. For these cases, it’s helpful to be able to enter a few keywords like queue priority, and have the search engine determine what you’re likely looking for.
Given BM25’s success in text search, it’s natural to wonder if it could work well for keyword-style code searches. After implementing it in Sourcegraph’s recent 6.2 release, our answer is “yes”! In our internal search quality evaluations, BM25 showed roughly 20% improvement across all key metrics compared to our baseline ranking.
It also performed well qualitatively — here’s what the search results look like before and after the change for a query against the Zoekt repository. Before, Sourcegraph ranked files highly even if they only had a strong match on one query term.
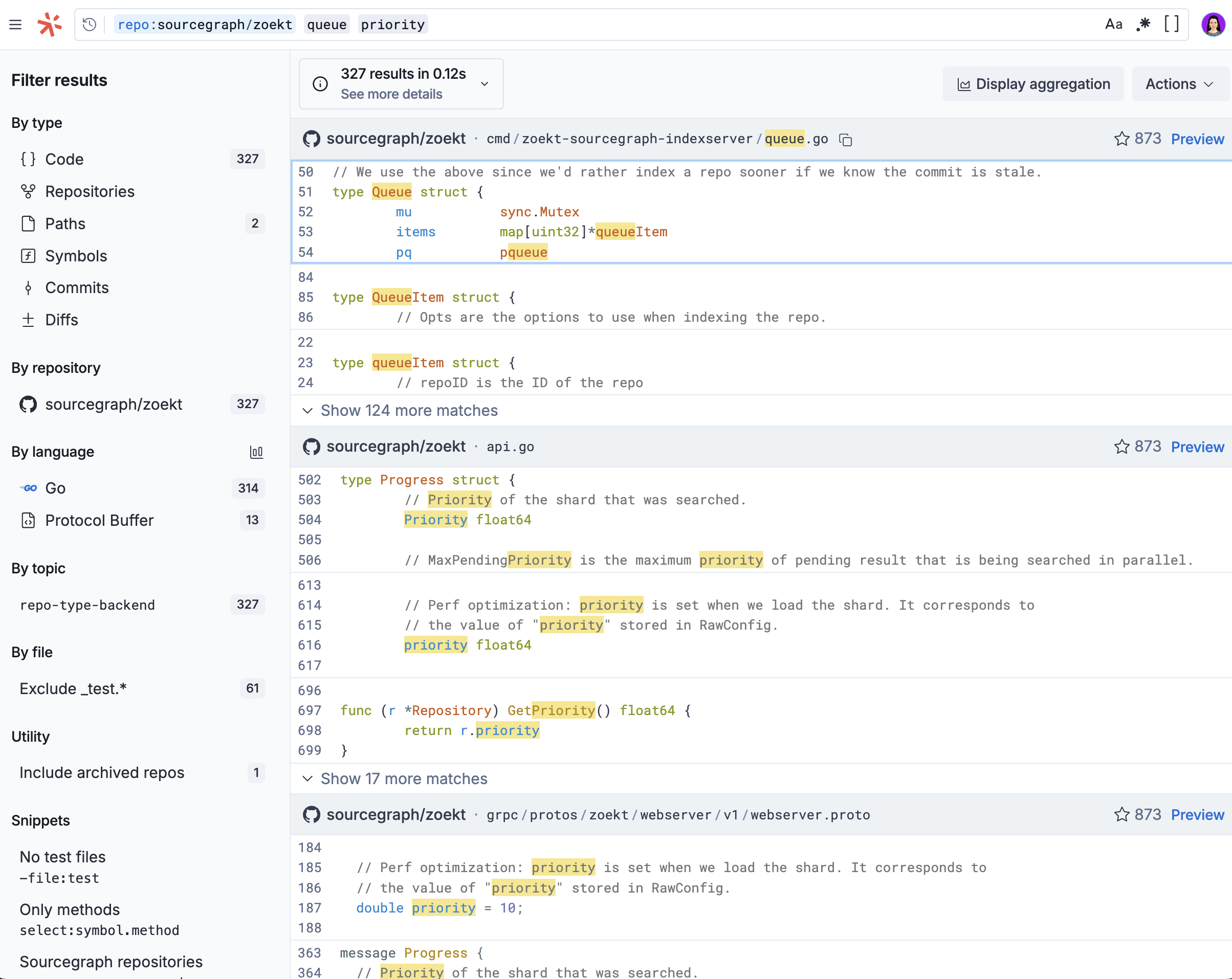
Now, the search results surface symbols like lastQueueItemPriority that are a strong match for the entire query.
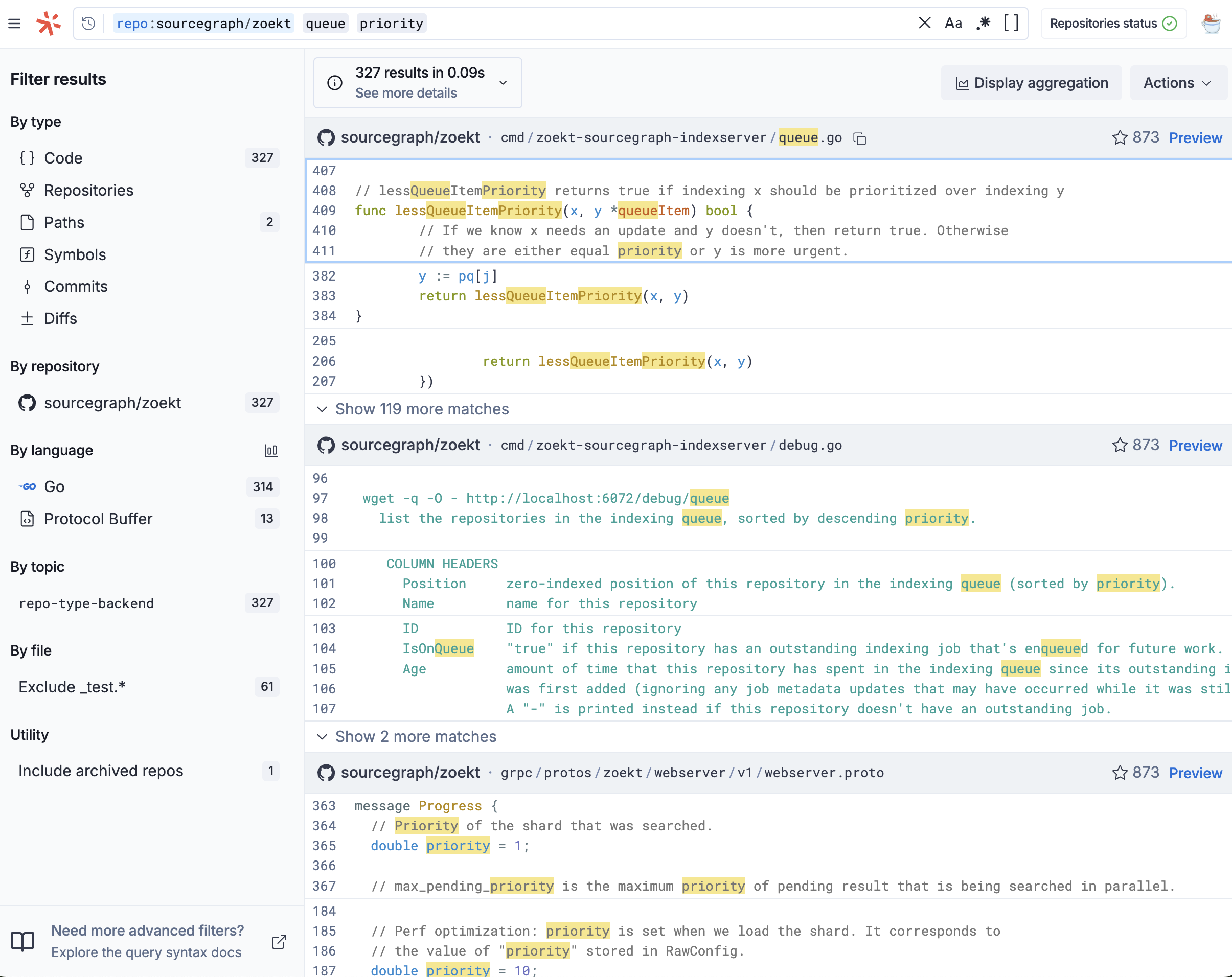
Although it’s a well-understood algorithm, it’s not immediately obvious how to apply BM25 to code search. A central issue we faced was that matches on file names and symbol definitions tend to be much more meaningful than those in the middle of a statement or comment. But BM25, being designed for text, treats all term matches the same. This post explores how we addressed this issue without sacrificing the properties that make BM25 shine: simplicity, interpretability, and strong zero-shot performance.
Extending BM25 to code
From a high level, BM25 ranks files by looking at the number of times each query term appears in the file. Given a single term from the query (like score), BM25 first calculates the number of times that term appears in each document, which is called the ‘term frequency’.
Compared to previous ranking algorithms like TF-IDF, BM25 makes a key improvement to how the term frequency is integrated into scoring. Specifically, the term frequency is passed through a “saturation function” to cap the influence of files with a huge number of term matches. This is intuitive, since a file that mentions score 500 times is not 100x more relevant than one that mentions it 5 times. And at some point more term matches doesn’t really mean “more relevant” at all!
The rate of saturation is impacted by the document length. BM25 ensures that term matches in shorter files are given more weight than matches in a longer file, to help prevent long files from dominating results simply because they have a lot of terms.
Here’s what the BM25 calculation looks like, in Golang-inspired pseudocode:
The BM25 algorithm traces its roots to the Probabilistic Relevance Framework, a conceptual model that ranks documents based on the log odds of them being relevant to an information need (or query). Outside of academic research, there are several great posts for understanding the BM25 algorithm in practical terms.
The problem of file structure
In code search ranking, it’s critical to reward matches on certain structural elements. If you search for extract tar, you likely want to see the function definition ExtractTar at the top of results. The same goes for file names: a query like vscode changelog should rank the client/vscode/CHANGELOG.md highly compared to files that just mention the terms vscode or changelog.
Sourcegraph search is powered by Zoekt, an open source code search engine. To support path matches, Zoekt already indexes filenames in addition to file contents. It also indexes symbol definitions to support symbol queries, which help power Sourcegraph’s “go to definition” code navigation feature. Zoekt extracts symbols using a combination of tree-sitter queries for common languages, plus universal-ctags to cover the “long tail” of languages without a high quality tree-sitter grammar.
It seems like we should be able to use these indexes to reward symbol and filename matches. But how can we do this within the BM25 framework? Perhaps we could think of contents, symbols, and filenames as different “fields” within a file, and sum the BM25 their scores like this:
This seems reasonable at first glance, but has some serious downsides. In practice, this gives too big an advantage to files with a match on multiple fields (like both content and filename), compared to an excellent match on just filename. This is because of BM25’s internal term frequency saturation, which discounts multiple matches on a single term.
And from a conceptual standpoint, this approach breaks with the probabilistic relevance framework, meaning it’s no longer clear how to interpret the final ranking. In general, principled approaches tend to be the most robust, and we try to only deviate if there’s a strong reason (preferably supported by data)!
Enter BM25F
As it turns out, information retrieval researchers have grappled with a very similar problem. Say you are searching articles, matching across title, abstract, and body fields, and you want matches on the title to count the most towards the final score. In Simple BM25 extension to multiple weighted fields, the authors extend BM25 to these sort of structured documents. Their algorithm, called BM25F, is built on a key insight: we can think of the document having just one big field that contains the combination of each field’s text. When scoring the document, we compute a single BM25 score over this single, combined field.
To reward matches on a specific field like title, we apply a boost to all its term frequencies before computing the BM25 score. Say we wanted matches on title to be 5 times as important as body — then all its term frequencies would be multiplied by 5 within the BM25 calculation. We can think of this as if all of the title’s words were repeated 5 times in the big combined field. Compared to the naive sum across fields, BM25F respects term saturation and avoids giving too much advantage to queries that match several fields.
We applied BM25F to incorporate matches on symbols and filenames, and it worked well right out-of-the-box. Our score calculation now looks roughly like this:
Where did the constant 5 come from here? We chose this boost by comparing a tiny grid of options against our internal evaluation datasets. Our tests showed that while applying a boost clearly improves search quality, the final ranking is not too sensitive to the exact choice of boost.
In retrospect, the idea behind BM25F feels quite simple, maybe even obvious. But as Blaise Pascal once wrote, “I have made this letter longer than usual because I have not had time to make it shorter.” Often the most effective approaches look deceptively simple, when they’re the result of much careful thought and experimentation behind-the-scenes.
Line-level scoring
When Zoekt indexes symbol definitions like QueueItem, it doesn’t just simply record what files it appears in. It also tracks the exact offsets in the file representing the definition’s span. This allows us to implement BM25F on a line-level as well: we compute the term frequencies for each line, boosting matches on symbols, while using the line’s length in place of the usual file length in BM25 calculation.
Specifically, the ranking takes these steps:
- Compute file-level BM25F to rank files by relevance to the query
- Then within each of those file results, compute line-level BM25F to determine the most relevant chunks to display first
This is closely related to the concept of “highlighting” in text search, which emphasizes the parts of each document most relevant to the user’s query. A common highlighting strategy is to break the text into sentences and use BM25 to score these individual sentences.
We can see line scoring in action through a query like cfg := readConfig. The top-scoring chunk contains all the query terms through the line cfg, err := readConfigURL(...). It’s displayed above a strong symbol match on the readConfigURL definition.
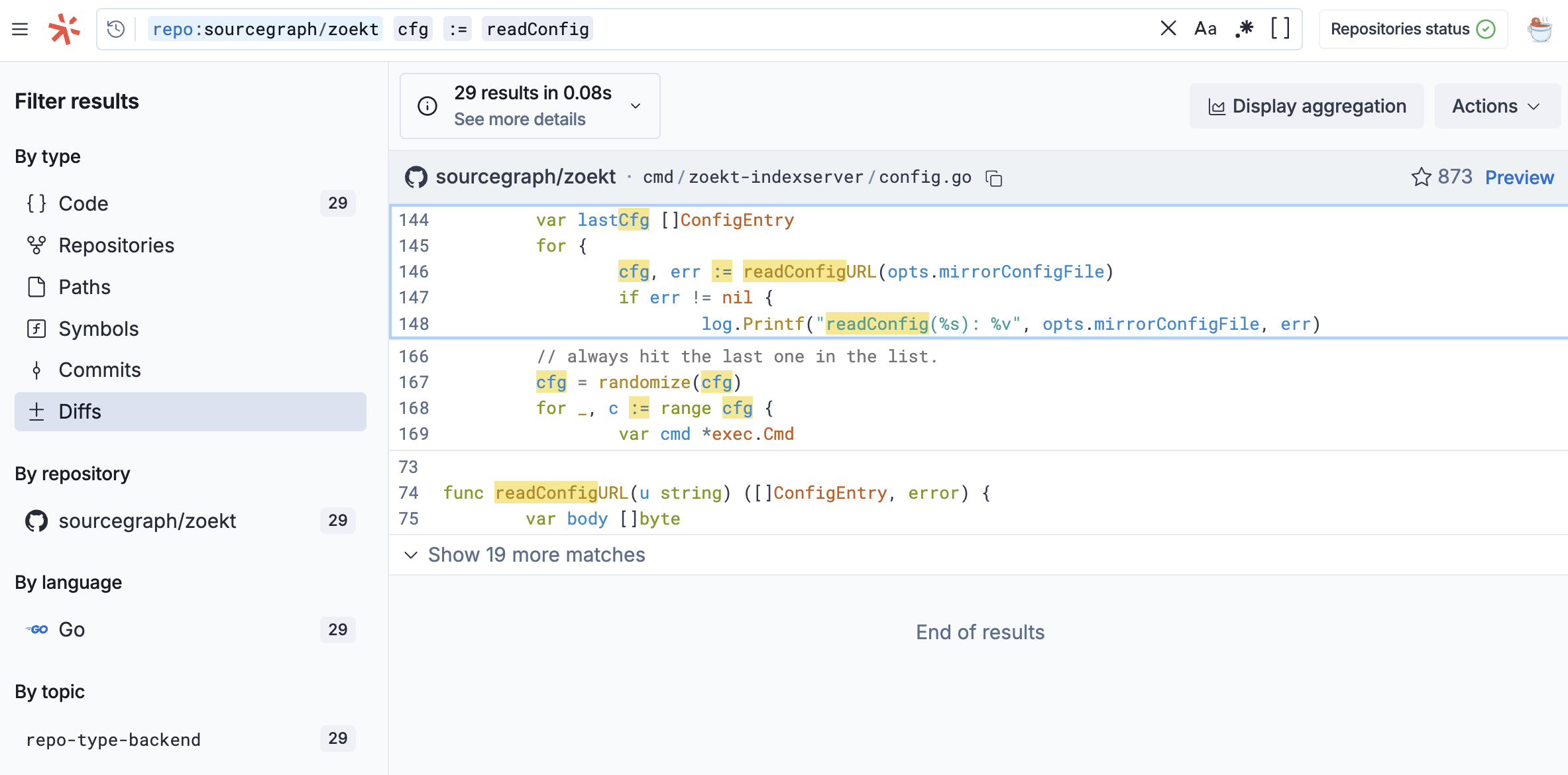
Not pictured here
This blog focuses on only one of the key insights in Sourcegraph’s ranking. Here we give a sense of how BM25 fits into an overall ranking strategy.
File-specific signals
In advanced search systems, ranking encompasses both query-file and file-specific signals. BM25 is a strong query-file signal, as it tries to capture the strength of the query-file match. Sourcegraph also incorporates file-specific signals like the file’s ‘category’ — is it a test, generated, third-party, etc., as well as signals drawn from git metadata like the number of recent commits.
Semantic search
In addition to the simple keyword-style search we’ve focused on so far, the Sourcegraph platform supports semantic code search, to help answer flexible questions about the codebase like “where do we skip binary files?” Semantic code search helps power capabilities like Agentic Chat, as a critical “tool” that aids the LLM in navigating a user’s codebase.
Sourcegraph’s semantic search follows a classic two-stage architecture, with a first-stage retrieval step optimized for recall, and a second-stage reranker focused on producing great top results. BM25 plays a key role in first stage retrieval, helping to gather a high quality candidate set. These candidates are then passed to a transformer model for second stage ranking. This step focuses on precision, performing a deep semantic comparison of the query and each file to determine which are most relevant.
Why are we still talking about BM25?
With all the exciting advances in the search field, from embeddings and vector search to emerging “agentic search” paradigms, it may seem surprising to put out a blog post on BM25 and keyword search. Here’s an earnest defense.
First, users (and LLMs) still need the lexical matching that keyword search provides. This is why many search systems are designed as “hybrid” architectures, where results from both keyword and embeddings retrievers are combined and reranked. At the same time, the search field is seeing a rise in “agentic” architectures, where an LLM interprets a user question, plans and formulates simple keyword search queries, and then repeatedly iterates to refine its answer. Systems like Claude Code have demonstrated that agentic search systems can produce high quality answers with only access to simple search tools based on lexical matches.
In academic work, BM25 has a consistently proven itself as a solid baseline, especially in zero-shot settings. To satisfy the needs of our diverse Enterprise customers, Sourcegraph must provide out-of-the-box support for “low resource” programming languages like COBOL85 or Mathematica. Some customers even use fully internal, proprietary languages with no publicly available examples! Because of its simplicity and interpretability, BM25 and keyword search lets us support customers in these challenging settings.
We confirmed these insights through our extensive internal code search evaluations, which test BM25, state-of-the-art embeddings models, semantic reranking, and their combination. When an algorithm has both the practical longevity and conceptual grounding of BM25, sometimes it’s worth a second (or third, or fourth?) look!
Appendix: a note on tokenization
While reading, you might have asked yourself: “Don’t we need a text search backend to do BM25, like Elasticsearch? How are you using a code search engine like Zoekt for this?” And you’d be right to wonder — due to their focus on substring and regex matching, code search engines tend work a bit differently “under the hood”.
Traditional text search backends tokenize the documents into individual terms during indexing, and store these terms in an inverted index. During search, they also tokenize queries in a compatible way, then match the query terms against the index. In contrast, most code search engines like Zoekt do not perform any index-time tokenization. In fact, tokenization is often considered at-odds with what code search users need: the ability to match punctuation exactly, and to match terms anywhere within a line, not just at pre-defined boundaries.
As a practical example, consider a keyword search like create pthread. It’s important that this match a method like pthread_create(). At the same time, a query like thread_create must work well too. It’s not easy to determine in advance how a term like pthread_create() should be tokenized to support these queries.
How should we make sense of BM25 in this substring-matching paradigm? Conceptually, we can imagine that each new query “induces” a tokenization on the corpus, where we split the text everywhere it matches one of the query terms. The lack of index-time tokenization does make it trickier to calculate the inverse document frequency (IDF), the other key part of BM25 besides term frequency. While tricky, this is not an insurmountable problem, as it’s possible to compute document frequencies (or close approximations to them) at search time.
.avif)
